回归算法概述
回归是另一种重要且广泛使用的统计和机器学习工具。基于回归的任务的主要目标是预测给定输入数据的连续数值的输出标签或响应。输出将基于模型在训练阶段学到的内容。基本上,回归模型使用输入数据特征(自变量)及其相应的连续数字输出值(因变量或结果变量)来学习输入和相应输出之间的特定关联。
回归模型的类型
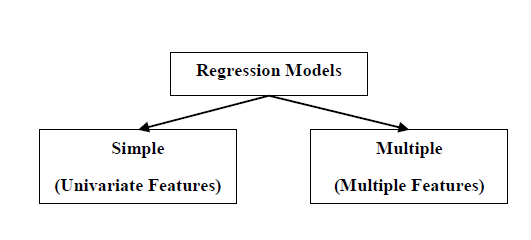
回归模型有以下两种:
简单回归模型 : 这是最基本的回归模型,其中预测是由数据的单一、单变量特征形成的。
多元回归模型 :顾名思义,在这个回归模型中,预测是由数据的多个特征形成的。
在 Python 中构建回归器
Python 中的回归模型可以像我们构建分类器一样构建。 Scikit-learn 是一个用于机器学习的 Python 库,也可用于在 Python 中构建回归器。
在以下示例中,我们将构建基本回归模型,该模型将拟合一条数据线,即线性回归器。在 Python 中构建回归器的必要步骤如下:
第一步:导入必要的python包
为了使用 scikit-learn 构建回归器,我们需要将其与其他必要的包一起导入。我们可以使用以下脚本导入:
import numpy as np from sklearn import linear_model import sklearn.metrics as sm import matplotlib.pyplot as plt
第 2 步:导入数据集
导入必要的包后,我们需要一个数据集来建立回归预测模型。我们可以从 sklearn 数据集中导入它,也可以根据我们的要求使用其他数据集。我们将使用我们保存的输入数据。我们可以借助以下脚本导入它:
input = r'C:\linear.txt'
接下来,我们需要加载这些数据。我们正在使用 np.loadtxt 函数来加载它。
input_data = np.loadtxt(input, delimiter=',') X, y = input_data[:, :-1], input_data[:, -1]
第 3 步:将数据组织成训练和测试集
由于我们需要在看不见的数据上测试我们的模型,因此我们将数据集分为两部分:训练集和测试集。以下命令将执行它:
training_samples = int(0.6 * len(X)) testing_samples = len(X) - num_training X_train, y_train = X[:training_samples], y[:training_samples] X_test, y_test = X[training_samples:], y[training_samples:]
第 4 步:模型评估和预测
将数据划分为训练和测试后,我们需要构建模型。为此,我们将使用 Scikit-learn 的 LineaRegression() 函数。以下命令将创建一个线性回归器对象。
reg_linear= linear_model.LinearRegression()
接下来,用训练样本训练这个模型如下:
reg_linear.fit(X_train, y_train)
现在,最后我们需要对测试数据进行预测。
y_test_pred = reg_linear.predict(X_test)
第 5 步:绘图和可视化
预测后,我们可以借助以下脚本对其进行绘图和可视化:
例子
plt.scatter(X_test, y_test, color='red') plt.plot(X_test, y_test_pred, color='black', linewidth=2) plt.xticks(()) plt.yticks(()) plt.show()
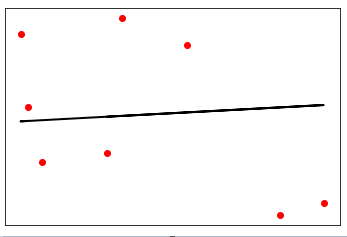
在上面的输出中,我们可以看到数据点之间的回归线。
第 6 步:性能计算
我们还可以借助各种性能指标计算回归模型的性能,如下所示:
例子
print("Regressor model performance:")
print("Mean absolute error(MAE) =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error(MSE) =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
Regressor model performance: Mean absolute error(MAE) = 1.78 Mean squared error(MSE) = 3.89 Median absolute error = 2.01 Explain variance score = -0.09 R2 score = -0.09
ML 回归算法的类型
最有用和流行的 ML 回归算法是线性回归算法,它进一步分为两种类型:
-
简单的线性回归算法
-
多元线性回归算法。
我们将在下一章讨论它并在 Python 中实现它。
应用
ML回归算法的应用如下:
预测或预测分析 :回归的重要用途之一是预测或预测分析。例如,我们可以预测 GDP、石油价格或简单地说随时间变化的定量数据。
优化 : 我们可以借助回归来优化业务流程。例如,商店经理可以创建一个统计模型来了解顾客光顾的时间。
纠错 : 在业务中,做出正确的决策与优化业务流程同样重要。回归可以帮助我们做出正确的决定,也可以纠正已经实施的决定。
经济学 : 是经济学中最常用的工具。我们可以使用回归来预测供应、需求、消费、库存投资等。
Finance : 一家金融公司总是对最小化风险组合感兴趣,想知道影响客户的因素。所有这些都可以在回归模型的帮助下进行预测。