KNN算法寻找最近的邻居
K-最近邻 (KNN) 算法是一种有监督的 ML 算法,可用于分类和回归预测问题。但是,它主要用于工业中的分类预测问题。以下两个属性可以很好地定义 KNN:
-
惰性学习算法 : KNN 是一种惰性学习算法,因为它没有专门的训练阶段,在分类的同时使用所有数据进行训练。
-
非参数学习算法 :KNN也是一种非参数学习算法,因为它不对底层数据做任何假设。
KNN算法的工作
K-最近邻(KNN)算法使用“特征相似性”来预测新数据点的值,这进一步意味着新数据点将根据它与训练集中的点的匹配程度来分配一个值。我们可以通过以下步骤了解它的工作原理:
-
步骤 1 :为了实现任何算法,我们都需要数据集。因此,在 KNN 的第一步中,我们必须加载训练数据和测试数据。
-
步骤 2 :接下来,我们需要选择K的值,即最近的数据点。 K 可以是任何整数。
-
步骤 3 : 对测试数据中的每个点做如下操作:
3.1 : 借助欧几里得距离、曼哈顿距离或汉明距离中的任何一种方法计算测试数据与每行训练数据的距离。最常用的距离计算方法是欧几里得。
3.2 : 现在,根据距离值,按升序排列。
3.3 :接下来会从排序后的数组中选择前K行。
3.4 : 现在,它将根据这些行中最频繁的类为测试点分配一个类。
-
步骤 4 : End
例子
下面是一个例子来理解K的概念和KNN算法的工作原理:
假设我们有一个数据集,可以绘制如下:
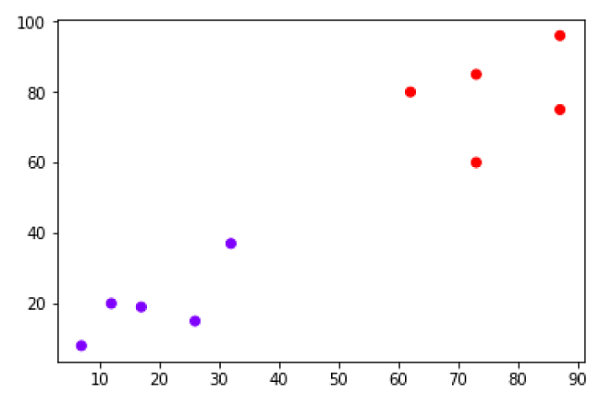
现在,我们需要将带有黑点的新数据点(在点 60,60)分类为蓝色或红色类。我们假设 K = 3,即它会找到三个最近的数据点。如下图所示:
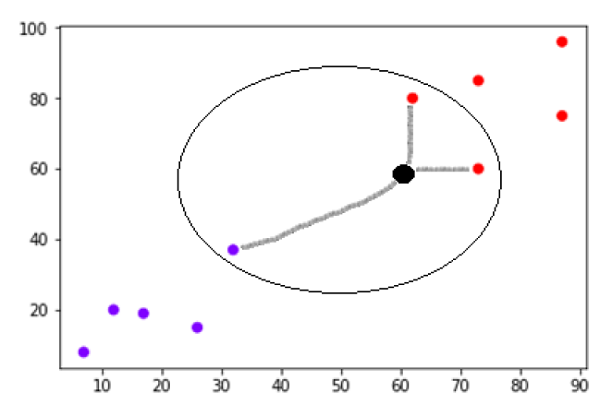
我们可以在上图中看到带有黑点的数据点的三个最近邻居。在这三个中,其中两个属于红色类,因此黑点也将被分配为红色类。
用 Python 实现
正如我们所知,K-最近邻(KNN)算法可用于分类和回归。以下是 Python 中使用 KNN 作为分类器和回归器的秘诀:
KNN 作为分类器
首先,从导入必要的python包开始:
import numpy as np import matplotlib.pyplot as plt import pandas as pd
接下来,从它的weblink下载鸢尾花数据集,如下:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下来,我们需要为数据集分配列名,如下所示:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
现在,我们需要将数据集读取到 pandas 数据帧,如下所示:
dataset = pd.read_csv(path, names=headernames) dataset.head()
| slno. | 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | Class |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 鸢尾花 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 鸢尾花 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 鸢尾花 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 鸢尾花 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 鸢尾花 |
数据预处理将在以下脚本行的帮助下完成:
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
接下来,我们将数据分为训练和测试拆分。以下代码将数据集拆分为 60% 的训练数据和 40% 的测试数据:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.40)
接下来,将进行数据缩放,如下所示:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
接下来,借助sklearn的KNeighborsClassifier类训练模型如下:
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=8) classifier.fit(X_train, y_train)
最后我们需要进行预测。可以借助以下脚本来完成:
y_pred = classifier.predict(X_test)
接下来,打印结果如下:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)
Confusion Matrix: [[21 0 0] [ 0 16 0] [ 0 7 16]] Classification Report: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 21 Iris-versicolor 0.70 1.00 0.82 16 Iris-virginica 1.00 0.70 0.82 23 micro avg 0.88 0.88 0.88 60 macro avg 0.90 0.90 0.88 60 weighted avg 0.92 0.88 0.88 60 Accuracy: 0.8833333333333333
KNN 作为回归器
首先,从导入必要的 Python 包开始:
import numpy as np import pandas as pd
接下来,从它的weblink下载鸢尾花数据集,如下:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下来,我们需要为数据集分配列名,如下所示:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
现在,我们需要将数据集读取到 pandas 数据帧,如下所示:
data = pd.read_csv(url, names=headernames) array = data.values X = array[:,:2] Y = array[:,2] data.shape output:(150, 5)
接下来,从 sklearn 中导入 KNeighborsRegressor 来拟合模型:
from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors=10) knnr.fit(X, y)
最后,我们可以找到MSE如下:
print ("The MSE is:",format(np.power(y-knnr.predict(X),2).mean()))
The MSE is: 0.12226666666666669
KNN 的优缺点
Pros
-
这是一个非常简单的算法,易于理解和解释。
-
它对于非线性数据非常有用,因为该算法中没有关于数据的假设。
-
它是一种通用算法,因为我们可以将它用于分类和回归。
-
它具有相对较高的准确性,但有比 KNN 更好的监督学习模型。
Cons
-
它在计算上是一个有点昂贵的算法,因为它存储了所有的训练数据。
-
与其他监督学习算法相比,需要高内存存储。
-
在大 N 的情况下预测很慢。
-
它对数据的规模以及不相关的特征非常敏感。
KNN 的应用
以下是一些可以成功应用KNN的领域:
银行系统
KNN 可以在银行系统中用于预测个人适合贷款审批的天气吗?该个人是否具有与违约者相似的特征?
计算信用等级
KNN 算法可用于通过与具有相似特征的人进行比较来找到个人的信用评级。
Politics
在 KNN 算法的帮助下,我们可以将潜在选民分为不同的类别,例如“将投票”、“不会投票”、“将投票给政党‘国会’、“将投票给政党‘BJP’。
其他可以使用 KNN 算法的领域是语音识别、手写检测、图像识别和视频识别。