支持向量机 (SVM)
支持向量机 (SVM) 是强大而灵活的监督机器学习算法,可用于分类和回归。但通常,它们用于分类问题。在 1960 年代,SVM 首次被引入,但后来在 1990 年得到改进。与其他机器学习算法相比,SVM 具有其独特的实现方式。最近,它们非常受欢迎,因为它们能够处理多个连续和分类变量。
支持向量机的工作
SVM 模型基本上是多维空间中超平面中不同类的表示。超平面将由 SVM 以迭代的方式生成,以使误差最小化。 SVM 的目标是将数据集划分为类以找到最大边际超平面 (MMH)。
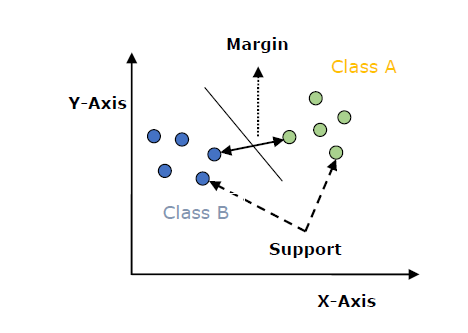
以下是 SVM 中的重要概念:
-
支持向量 :离超平面最近的数据点称为支持向量。将在这些数据点的帮助下定义分隔线。
-
超平面 : 如上图所示,它是一个决策平面或空间,被划分为一组具有不同类别的对象。
-
Margin : 可以定义为不同类最接近的数据点上两条线之间的差距。它可以计算为从直线到支持向量的垂直距离。大边距被认为是好的边距,小边距被认为是坏边距。
支持向量机的主要目标是将数据集划分为类以找到最大边缘超平面(MMH),可以通过以下两个步骤完成:
-
首先,SVM 将迭代生成超平面,以最佳方式分离类。
-
然后,它将选择正确分离类的超平面。
在 Python 中实现 SVM
为了在 Python 中实现 SVM,我们将从标准库导入开始,如下所示:
import numpy as np import matplotlib.pyplot as plt from scipy import stats import seaborn as sns; sns.set()
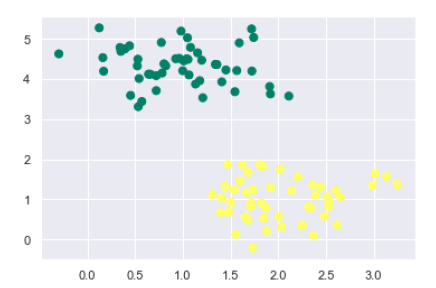
接下来,我们从 sklearn.dataset.sample_generator 创建一个具有线性可分数据的样本数据集,用于使用 SVM 进行分类:
from sklearn.datasets.samples_generator import make_blobs X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.50) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer');
以下是生成包含 100 个样本和 2 个聚类的样本数据集后的输出:
我们知道 SVM 支持判别分类。它通过在二维的情况下简单地找到一条线或在多维的情况下找到流形来将类彼此划分。在上述数据集上实现如下:
xfit = np.linspace(-1, 3.5) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') plt.plot([0.6], [2.1], 'x', color='black', markeredgewidth=4, markersize=12) for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]: plt.plot(xfit, m * xfit + b, '-k') plt.xlim(-1, 3.5);
输出如下:
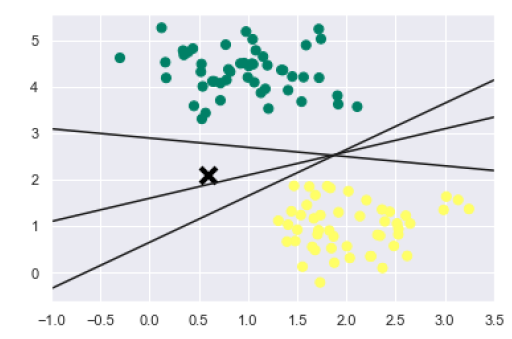
我们可以从上面的输出中看到,有三种不同的分离器可以完美区分上述样本。
如前所述,SVM 的主要目标是将数据集划分为类以找到最大边际超平面 (MMH),因此我们可以在每条线周围画出到最近点的一定宽度的边距,而不是在类之间画一条零线。可以这样做:
xfit = np.linspace(-1, 3.5) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]: yfit = m * xfit + b plt.plot(xfit, yfit, '-k') plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none', color='#AAAAAA', alpha=0.4) plt.xlim(-1, 3.5);
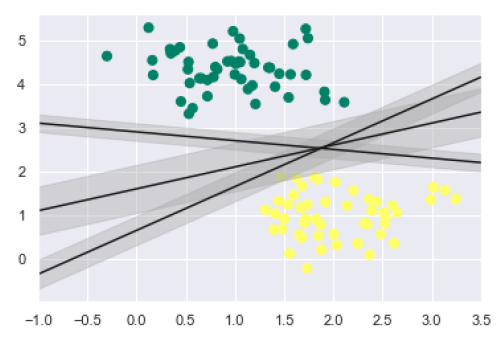
从上面输出的图像中,我们可以很容易地观察到判别分类器中的“边缘”。 SVM 将选择最大化边距的线。
接下来,我们将使用 Scikit-Learn 的支持向量分类器在这些数据上训练一个 SVM 模型。在这里,我们使用线性核来拟合 SVM,如下所示:
from sklearn.svm import SVC # "Support vector classifier" model = SVC(kernel='linear', C=1E10) model.fit(X, y)
输出如下:
SVC(C=10000000000.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto_deprecated', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
现在,为了更好地理解,下面将绘制 2D SVC 的决策函数:
def decision_function(model, ax=None, plot_support=True): if ax is None: ax = plt.gca() xlim = ax.get_xlim() ylim = ax.get_ylim()
为了评估模型,我们需要创建网格如下:
x = np.linspace(xlim[0], xlim[1], 30) y = np.linspace(ylim[0], ylim[1], 30) Y, X = np.meshgrid(y, x) xy = np.vstack([X.ravel(), Y.ravel()]).T P = model.decision_function(xy).reshape(X.shape)
接下来,我们需要绘制决策边界和边距,如下所示:
ax.contour(X, Y, P, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
现在,类似地绘制支持向量如下:
if plot_support: ax.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=300, linewidth=1, facecolors='none'); ax.set_xlim(xlim) ax.set_ylim(ylim)
现在,使用这个函数来拟合我们的模型,如下所示:
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='summer') decision_function(model);

我们可以从上面的输出中观察到,SVM 分类器适合带有边距的数据,即虚线和支持向量,这种适合的关键元素与虚线接触。这些支持向量点存储在分类器的support_vectors_属性中如下:
model.support_vectors_
输出如下:
array([[0.5323772 , 3.31338909], [2.11114739, 3.57660449], [1.46870582, 1.86947425]])
支持向量机内核
在实践中,SVM 算法是使用内核实现的,该内核将输入数据空间转换为所需的形式。 SVM 使用一种称为内核技巧的技术,其中内核采用低维输入空间并将其转换为高维空间。简而言之,内核通过向其添加更多维度将不可分离的问题转换为可分离的问题。它使 SVM 更加强大、灵活和准确。以下是 SVM 使用的一些内核类型:
线性内核
它可以用作任意两个观测值之间的点积。线性核的公式如下:
k(x,x i ) = 总和(x*x i )
从上面的公式我们可以看出,两个向量之间的乘积 ? & ?? 是每对输入值的乘积之和。
多项式核
它是线性核的更广义形式,可以区分弯曲或非线性输入空间。以下是多项式核的公式:
K(x, xi) = 1 + sum(x * xi)^d
这里d是多项式的次数,我们需要在学习算法中手动指定。
径向基函数 (RBF) 内核
RBF 核,主要用于 SVM 分类,将输入空间映射到不定维空间中。下面的公式从数学上解释它:
K(x,xi) = exp(-gamma * sum((x – xi^2))
这里,gamma 的范围是 0 到 1。我们需要在学习算法中手动指定它。 gamma 的一个好的默认值是 0.1。
由于我们为线性可分数据实现了 SVM,我们可以在 Python 中为不可线性可分的数据实现它。它可以通过使用内核来完成。
例子
以下是使用内核创建 SVM 分类器的示例。我们将使用来自 scikit-learn 的 iris 数据集:
我们将从导入以下包开始:
import pandas as pd import numpy as np from sklearn import svm, datasets import matplotlib.pyplot as plt
现在,我们需要加载输入数据:
iris = datasets.load_iris()
从这个数据集中,我们获取前两个特征如下:
X = iris.data[:, :2] y = iris.target
接下来,我们将使用原始数据绘制 SVM 边界,如下所示:
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 h = (x_max / x_min)/100 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) X_plot = np.c_[xx.ravel(), yy.ravel()]
现在,我们需要提供正则化参数的值,如下所示:
C = 1.0
接下来,可以如下创建 SVM 分类器对象:
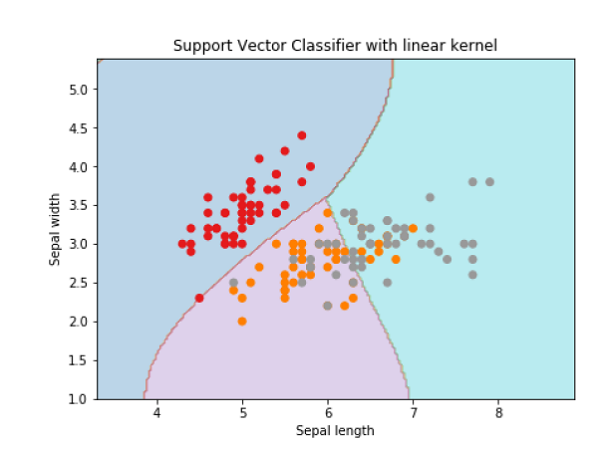
Svc_classifier = svm.SVC(kernel='linear', C=C).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with linear kernel')
Text(0.5, 1.0, 'Support Vector Classifier with linear kernel')
用于创建 SVM 分类器 rbf 内核,我们可以将内核更改为 rbf 如下:
Svc_classifier = svm.SVC(kernel='rbf', gamma =‘auto’,C=C).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('Support Vector Classifier with rbf kernel')
Text(0.5, 1.0, 'Support Vector Classifier with rbf kernel')
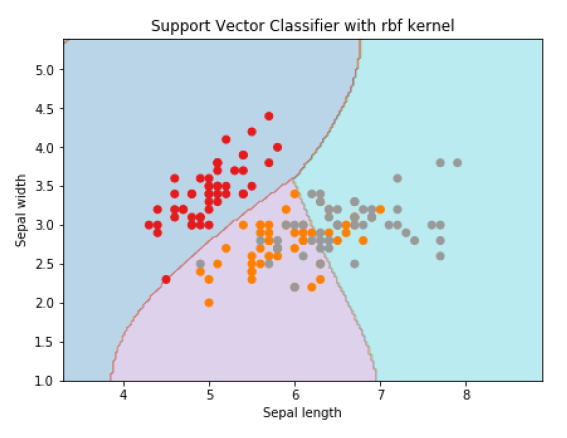
我们将 gamma 的值设置为“auto”,但你也可以提供 0 到 1 之间的值。
SVM 分类器的优缺点
SVM 分类器的优点
SVM 分类器提供了很高的准确性,并且在高维空间中工作得很好。 SVM 分类器基本上使用训练点的子集,因此结果使用的内存非常少。
SVM 分类器的缺点
它们的训练时间很长,因此在实践中不适合大型数据集。另一个缺点是 SVM 分类器不能很好地处理重叠类。