分类算法决策树
一般来说,决策树分析是一种预测建模工具,可以应用于许多领域。决策树可以通过算法方法构建,该算法可以根据不同的条件以不同的方式拆分数据集。决策树是最强大的算法,属于监督算法的范畴。
它们可用于分类和回归任务。树的两个主要实体是决策节点,数据在这里被分割和离开,我们得到结果。下面给出一个用于预测一个人是否健康的二叉树示例,它提供了年龄、饮食习惯和运动习惯等各种信息:
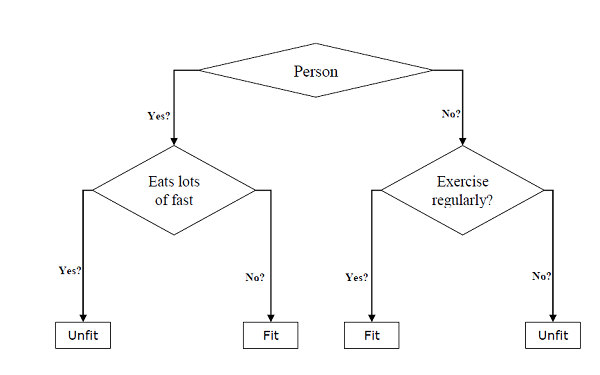
在上面的决策树中,问题是决策节点,最终结果是叶子。我们有以下两种类型的决策树:
-
分类决策树 : 在这种决策树中,决策变量是分类的。上面的决策树是分类决策树的一个例子。
-
回归决策树 : 在这种决策树中,决策变量是连续的。
实现决策树算法
基尼指数
它是成本函数的名称,用于评估数据集中的二元拆分,并与类别目标变量“成功”或“失败”一起使用。
基尼指数值越高,同质性越高。完美的基尼指数值为 0,最差的是 0.5(对于 2 类问题)。拆分的基尼指数可以通过以下步骤计算:
-
首先,使用公式 p^2+q^2 计算子节点的基尼指数,即成功和失败概率的平方和。
-
接下来,使用该拆分的每个节点的加权 Gini 得分计算拆分的 Gini 指数。
分类和回归树 (CART) 算法使用 Gini 方法生成二元拆分。
拆分创建
拆分基本上包括数据集中的一个属性和一个值。我们可以在以下三个部分的帮助下创建数据集拆分:
-
第 1 部分:计算基尼值 : 上一节我们刚刚讨论过这部分。
-
第 2 部分:拆分数据集 : 可以定义为将一个数据集分成两个行列表,具有属性的索引和该属性的拆分值。从数据集中得到左右两组后,我们可以使用第一部分计算的基尼分数来计算分割的值。拆分值将决定属性将驻留在哪个组中。
-
第 3 部分:评估所有拆分 : 找到Gini score和split dataset之后的下一部分是对所有split的评估。为此,首先,我们必须检查与每个属性关联的每个值作为候选拆分。然后我们需要通过评估拆分的成本来找到可能的最佳拆分。最佳分割将用作决策树中的一个节点。
建造一棵树
我们知道一棵树有根节点和终端节点。创建根节点后,我们可以通过以下两部分来构建树:
Part1:终端节点创建
在创建决策树的终端节点时,重要的一点是决定何时停止生长树或创建更多的终端节点。可以通过使用最大树深度和最小节点记录两个标准来完成,如下所示:
-
最大树深 :顾名思义,这是树中根节点之后的最大节点数。一旦树达到最大深度,即一旦树获得最大数量的终端节点,我们必须停止添加终端节点。
-
最小节点记录 :可以定义为给定节点负责的最小训练模式数。一旦树达到这些最小节点记录或低于此最小值,我们必须停止添加终端节点。
终端节点用于进行最终预测。
Part2:递归拆分
正如我们了解何时创建终端节点一样,现在我们可以开始构建我们的树了。递归拆分是一种构建树的方法。在这种方法中,一旦创建了一个节点,我们就可以在每组数据上递归地创建子节点(添加到现有节点的节点),这些数据是通过拆分数据集生成的,通过一次又一次地调用相同的函数。
预言
构建决策树后,我们需要对其进行预测。基本上,预测涉及使用专门提供的数据行导航决策树。
如上所述,我们可以借助递归函数进行预测。使用左节点或右子节点再次调用相同的预测例程。
假设
以下是我们在创建决策树时所做的一些假设:
-
在准备决策树时,训练集作为根节点。
-
决策树分类器更喜欢特征值是分类的。如果你想使用连续值,则必须在模型构建之前对其进行离散化。
-
根据属性的值,递归分布记录。
-
统计方法将用于将属性放置在任何节点位置,即作为根节点或内部节点。
用 Python 实现
例子
在下面的例子中,我们将在 Pima Indian Diabetes 上实现决策树分类器:
首先,从导入必要的python包开始:
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split
接下来,从它的weblink下载鸢尾花数据集,如下:
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label'] pima = pd.read_csv(r"C:\pima-indians-diabetes.csv", header=None, names=col_names) pima.head()
pregnant glucose bp skin insulin bmi pedigree age label 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1 3 1 89 66 23 94 28.1 0.167 21 0 4 0 137 40 35 168 43.1 2.288 33 1
现在,将数据集拆分为特征和目标变量,如下所示:
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree'] X = pima[feature_cols] # Features y = pima.label # Target variable
接下来,我们将数据分为训练和测试拆分。以下代码将数据集拆分为 70% 的训练数据和 30% 的测试数据:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
接下来,借助sklearn的DecisionTreeClassifier类训练模型如下:
clf = DecisionTreeClassifier() clf = clf.fit(X_train,y_train)
最后我们需要进行预测。可以借助以下脚本来完成:
y_pred = clf.predict(X_test)
接下来,我们可以得到准确率分数、混淆矩阵和分类报告如下:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)
Confusion Matrix: [[116 30] [ 46 39]] Classification Report: precision recall f1-score support 0 0.72 0.79 0.75 146 1 0.57 0.46 0.51 85 micro avg 0.67 0.67 0.67 231 macro avg 0.64 0.63 0.63 231 weighted avg 0.66 0.67 0.66 231 Accuracy: 0.670995670995671
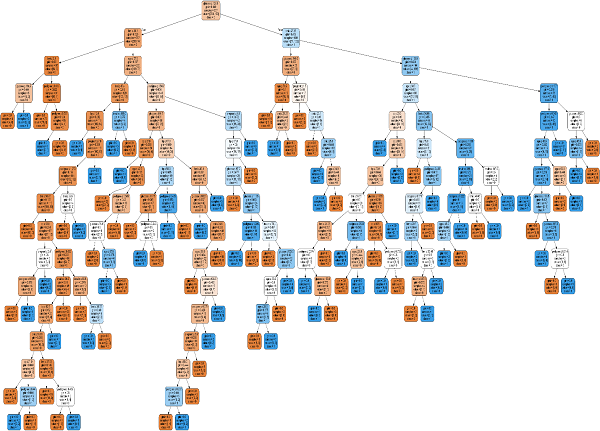
可视化决策树
上面的决策树可以借助以下代码进行可视化:
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('Pima_diabetes_Tree.png')
Image(graph.create_png())