ML 通过可视化理解数据
在上一章中,我们讨论了数据对于机器学习算法的重要性以及一些 Python 秘诀,以通过统计来理解数据。还有另一种称为可视化的方法来理解数据。
在数据可视化的帮助下,我们可以看到数据的样子,以及数据的属性之间具有什么样的相关性。这是查看特征是否与输出对应的最快方法。在以下 Python 食谱的帮助下,我们可以通过统计来理解 ML 数据。
单变量图:独立理解属性
最简单的可视化类型是单变量或“单变量”可视化。借助单变量可视化,我们可以独立理解数据集的每个属性。以下是Python中实现单变量可视化的一些技巧:
直方图
直方图将数据分组到 bin 中,是了解数据集中每个属性分布的最快方法。以下是直方图的一些特征:
-
它为我们提供了为可视化创建的每个 bin 中的观察数量的计数。
-
从箱的形状,我们可以很容易地观察到分布,即天气它是高斯的、偏斜的或指数的。
-
直方图还可以帮助我们查看可能的异常值。
例子
下面显示的代码是创建 Pima Indian Diabetes 数据集属性直方图的 Python 脚本示例。在这里,我们将在 Pandas DataFrame 上使用 hist() 函数来生成直方图和 matplotlib 用于绘制它们。
from matplotlib import pyplot from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) data.hist() pyplot.show()
输出
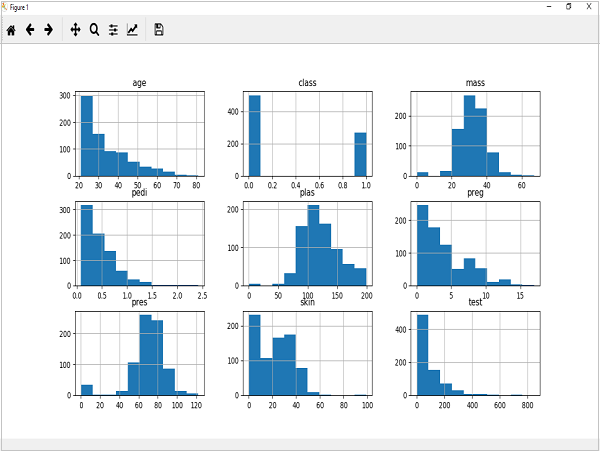
上面的输出显示它为数据集中的每个属性创建了直方图。由此,我们可以观察到年龄、pedi 和 test 属性可能呈指数分布,而 mass 和 plas 呈高斯分布。
密度图
获取每个属性分布的另一种快速简便的技术是密度图。它也类似于直方图,但在每个 bin 的顶部绘制了一条平滑曲线。我们可以称它们为抽象直方图。
例子
在以下示例中,Python 脚本将为 Pima Indian Diabetes 数据集的属性分布生成密度图。
from matplotlib import pyplot from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) data.plot(kind='density', subplots=True, layout=(3,3), sharex=False) pyplot.show()

从上面的输出中,可以很容易地理解密度图和直方图之间的区别。
箱须图
箱线图,简称箱线图,是另一种检查每个属性分布的有用技术。该技术的特点如下:
-
它本质上是单变量的,总结了每个属性的分布。
-
它为中间值绘制一条线,即中值。
-
它在 25% 和 75% 周围画了一个框。
-
它还绘制了胡须,这将使我们对数据的传播有所了解。
-
晶须外的点表示异常值。离群值将是中间数据分布大小的 1.5 倍。
例子
在以下示例中,Python 脚本将为 Pima Indian Diabetes 数据集的属性分布生成密度图。
from matplotlib import pyplot from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) data.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False) pyplot.show()
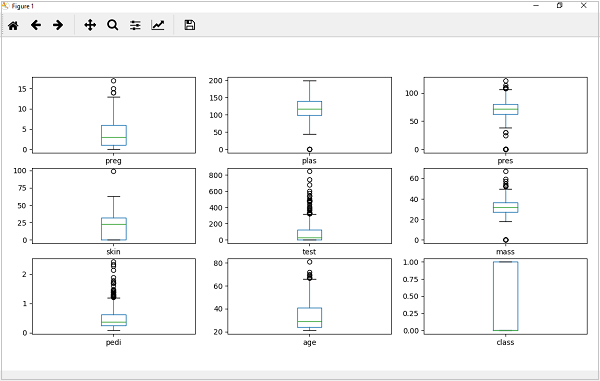
从上面的属性分布图可以看出,年龄、测试和皮肤似乎偏向较小的值。
多元图:多个变量之间的相互作用
另一种可视化类型是多变量或“多变量”可视化。借助多元可视化,我们可以了解数据集的多个属性之间的交互。以下是Python中实现多元可视化的一些技巧:
相关矩阵图
相关性是关于两个变量之间变化的指示。在我们之前的章节中,我们也讨论了皮尔逊相关系数以及相关性的重要性。我们可以绘制相关矩阵来显示哪个变量相对于另一个变量具有高或低相关性。
例子
在以下示例中,Python 脚本将为 Pima Indian Diabetes 数据集生成并绘制相关矩阵。它可以在 Pandas DataFrame 上的 corr() 函数的帮助下生成,并在 pyplot 的帮助下绘制。
from matplotlib import pyplot from pandas import read_csv import numpy Path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(Path, names=names) correlations = data.corr() fig = pyplot.figure() ax = fig.add_subplot(111) cax = ax.matshow(correlations, vmin=-1, vmax=1) fig.colorbar(cax) ticks = numpy.arange(0,9,1) ax.set_xticks(ticks) ax.set_yticks(ticks) ax.set_xticklabels(names) ax.set_yticklabels(names) pyplot.show()

从相关矩阵的上述输出中,我们可以看到它是对称的,即左下角与右上角相同。还观察到每个变量彼此之间呈正相关。
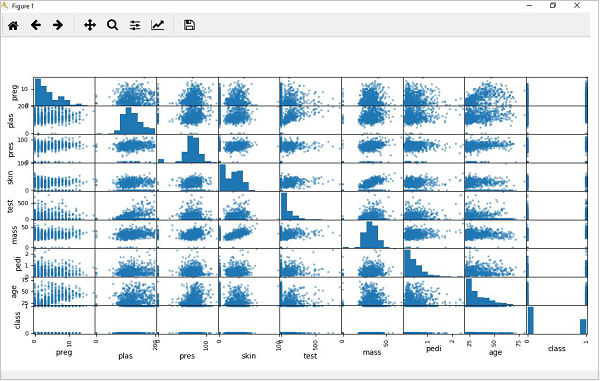
散点矩阵图
散点图通过二维点的帮助显示一个变量受另一个变量的影响程度或它们之间的关系。散点图在概念上非常类似于折线图,它们使用水平轴和垂直轴来绘制数据点。
例子
在以下示例中,Python 脚本将为 Pima Indian Diabetes 数据集生成并绘制散点矩阵。它可以在 Pandas DataFrame 上的 scatter_matrix() 函数的帮助下生成,并在 pyplot 的帮助下绘制。
from matplotlib import pyplot from pandas import read_csv from pandas.tools.plotting import scatter_matrix path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) scatter_matrix(data) pyplot.show()