SciPy CSGraph
CSGraph 代表 压缩稀疏图 ,它专注于基于稀疏矩阵表示的快速图算法。
图形表示
首先,让我们了解什么是稀疏图以及它如何帮助图表示。
什么是稀疏图?
图只是节点的集合,它们之间有链接。图表几乎可以表示任何东西:社交网络连接,其中每个节点都是一个人并与熟人相连;图像,其中每个节点是一个像素并连接到相邻像素;高维分布中的点,其中每个节点都连接到其最近的邻居;几乎所有你能想象到的东西。
表示图数据的一种非常有效的方法是在稀疏矩阵中:我们称其为 G。矩阵 G 的大小为 N x N,G[i, j] 给出了节点“i”和节点之间的连接值'j'。稀疏图主要包含零:即大多数节点只有很少的连接。在大多数感兴趣的情况下,这个属性被证明是正确的。
创建稀疏图子模块的动机是 scikit-learn 中使用的几种算法,其中包括:
-
Isomap : 流形学习算法,需要在图中找到最短路径。
-
层次聚类 :一种基于最小生成树的聚类算法。
-
光谱分解 :一种基于稀疏图拉普拉斯算子的投影算法。
作为一个具体的例子,假设我们想表示如下的无向图:
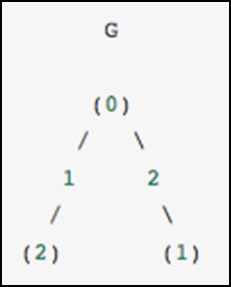
该图有三个节点,其中节点 0 和 1 由权重为 2 的边连接,节点 0 和 2 由权重为 1 的边连接。我们可以构造密集、掩蔽和稀疏表示,如下例所示,请记住,无向图由对称矩阵表示。
G_dense = np.array([ [0, 2, 1], [2, 0, 0], [1, 0, 0] ]) G_masked = np.ma.masked_values(G_dense, 0) from scipy.sparse import csr_matrix G_sparse = csr_matrix(G_dense) print G_sparse.data
上述程序将生成以下输出。
array([2, 1, 2, 1])
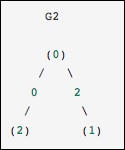
这与上一个图相同,除了节点 0 和 2 由零权重的边连接。在这种情况下,上面的密集表示会导致歧义:如果零是有意义的值,如何表示非边。在这种情况下,必须使用屏蔽或稀疏表示来消除歧义。
让我们考虑下面的例子。
from scipy.sparse.csgraph import csgraph_from_dense G2_data = np.array ([ [np.inf, 2, 0 ], [2, np.inf, np.inf], [0, np.inf, np.inf] ]) G2_sparse = csgraph_from_dense(G2_data, null_value=np.inf) print G2_sparse.data
上述程序将生成以下输出。
array([ 2., 0., 2., 0.])
使用稀疏图的字梯
字梯是刘易斯卡罗尔发明的一种游戏,其中单词通过在每一步更改一个字母来连接。例如:
APE → APT → AIT → BIT → BIG → BAG → MAG → MAN
在这里,我们分七个步骤从“APE”到“MAN”,每次改变一个字母。问题是 - 我们可以使用相同的规则在这些词之间找到更短的路径吗?这个问题很自然地表示为稀疏图问题。节点将对应于单个单词,我们将在最多相差一个字母的单词之间创建连接。
获取单词列表
首先,当然,我们必须获得一个有效词的列表。我正在运行 Mac,Mac 在以下代码块中给出的位置有一个字典。如果你在不同的架构上,你可能需要搜索一下才能找到你的系统字典。
wordlist = open('/usr/share/dict/words').read().split()
print len(wordlist)
上述程序将生成以下输出。
235886
我们现在要查看长度为 3 的单词,所以让我们只选择那些长度正确的单词。我们还将删除以大写字母(专有名词)开头或包含非字母数字字符(如撇号和连字符)的单词。最后,我们将确保所有内容都是小写的,以便稍后进行比较。
word_list = [word for word in word_list if len(word) == 3] word_list = [word for word in word_list if word[0].islower()] word_list = [word for word in word_list if word.isalpha()] word_list = map(str.lower, word_list) print len(word_list)
上述程序将生成以下输出。
1135
现在,我们有一个包含 1135 个有效三字母单词的列表(确切的数字可能会根据使用的特定列表而变化)。这些单词中的每一个都将成为我们图中的一个节点,并且我们将创建连接与每对单词关联的节点的边,它们仅相差一个字母。
import numpy as np word_list = np.asarray(word_list) word_list.dtype word_list.sort() word_bytes = np.ndarray((word_list.size, word_list.itemsize), dtype = 'int8', buffer = word_list.data) print word_bytes.shape
上述程序将生成以下输出。
(1135, 3)
我们将使用每个点之间的汉明距离来确定哪些词对是连接的。汉明距离衡量两个向量之间的条目比例,这两个向量不同:汉明距离等于 1/N1/N 的任何两个单词,其中 NN 是在单词阶梯中连接的字母数。
from scipy.spatial.distance import pdist, squareform from scipy.sparse import csr_matrix hamming_dist = pdist(word_bytes, metric = 'hamming') graph = csr_matrix(squareform(hamming_dist < 1.5 / word_list.itemsize))
在比较距离时,我们不使用等式,因为这对于浮点值可能是不稳定的。只要单词列表中没有两个条目相同,不等式就会产生所需的结果。现在,我们的图已经设置好了,我们将使用最短路径搜索来查找图中任意两个单词之间的路径。
i1 = word_list.searchsorted('ape')
i2 = word_list.searchsorted('man')
print word_list[i1],word_list[i2]
上述程序将生成以下输出。
ape, man
我们需要检查这些匹配,因为如果单词不在列表中,输出中就会出错。现在,我们只需要在图中找到这两个索引之间的最短路径。我们将使用 迪杰斯特拉 算法,因为它允许我们只找到一个节点的路径。
from scipy.sparse.csgraph import dijkstra distances, predecessors = dijkstra(graph, indices = i1, return_predecessors = True) print distances[i2]
上述程序将生成以下输出。
5.0
因此,我们看到“猿”和“人”之间的最短路径仅包含五个步骤。我们可以使用算法返回的前辈来重构这条路径。
path = [] i = i2 while i != i1: path.append(word_list[i]) i = predecessors[i] path.append(word_list[i1]) print path[::-1]i2]
上述程序将生成以下输出。
['ape', 'ope', 'opt', 'oat', 'mat', 'man']