Spark 介绍
行业正在广泛使用 Hadoop 来分析他们的数据集。原因是 Hadoop 框架基于简单的编程模型 (MapReduce),它支持可扩展、灵活、容错和成本有效的计算解决方案。在这里,主要关注的是在查询之间的等待时间和运行程序的等待时间方面保持处理大型数据集的速度。
Spark 由 Apache Software Foundation 引入,用于加速 Hadoop 计算计算软件过程。
与普遍的信念相反, Spark 不是 Hadoop 的修改版本 并且实际上并不依赖于 Hadoop,因为它有自己的集群管理。 Hadoop 只是实现 Spark 的方法之一。
Spark 以两种方式使用 Hadoop——一种是 storage 第二个是 加工 .由于 Spark 有自己的集群管理计算,它仅将 Hadoop 用于存储目的。
阿帕奇星火
Apache Spark 是一种闪电般快速的集群计算技术,专为快速计算而设计。它基于 Hadoop MapReduce 并扩展了 MapReduce 模型以有效地将其用于更多类型的计算,包括交互式查询和流处理。 Spark的主要特点是 内存集群计算 这提高了应用程序的处理速度。
Spark 旨在涵盖广泛的工作负载,例如批处理应用程序、迭代算法、交互式查询和流式传输。除了支持相应系统中的所有这些工作负载外,它还减轻了维护单独工具的管理负担。
Apache Spark 的演变
Spark 是 Matei Zaharia 于 2009 年在加州大学伯克利分校的 AMPLab 开发的 Hadoop 子项目之一。它于 2010 年在 BSD 许可下开源。它于 2013 年捐赠给 Apache 软件基金会,现在 Apache Spark 从 2014 年 2 月开始成为顶级 Apache 项目。
Apache Spark 的特点
Apache Spark 具有以下特性。
-
Speed : Spark 有助于在 Hadoop 集群中运行应用程序,在内存中速度提高 100 倍,在磁盘上运行时速度提高 10 倍。这可以通过减少对磁盘的读/写操作的数量来实现。它将中间处理数据存储在内存中。
-
支持多种语言 : Spark 提供了 Java、Scala 或 Python 的内置 API。因此,你可以用不同的语言编写应用程序。 Spark 为交互式查询提供了 80 个高级运算符。
-
高级分析 : Spark不仅支持‘Map’和‘reduce’。它还支持 SQL 查询、流数据、机器学习 (ML) 和图形算法。
基于 Hadoop 构建的 Spark
下图显示了如何使用 Hadoop 组件构建 Spark 的三种方式。
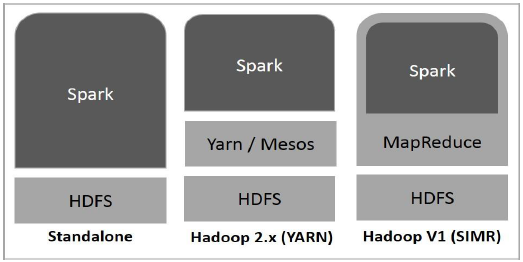
Spark 部署的三种方式如下所述。
-
独立 : Spark Standalone部署意味着Spark占据HDFS(Hadoop分布式文件系统)之上的位置,并且明确地为HDFS分配空间。在这里,Spark 和 MapReduce 将并行运行以覆盖集群上的所有 Spark 作业。
-
Hadoop纱线 : Hadoop Yarn 部署意味着,简单地说,Spark 在 Yarn 上运行,无需任何预安装或 root 访问权限。它有助于将 Spark 集成到 Hadoop 生态系统或 Hadoop 堆栈中。它允许其他组件在堆栈顶部运行。
-
MapReduce 中的 Spark (SIMR) : MapReduce 中的 Spark 除了独立部署外,还用于启动 Spark 作业。使用 SIMR,用户无需任何管理权限即可启动 Spark 并使用其 shell。
Spark的组件
下图描述了 Spark 的不同组件。
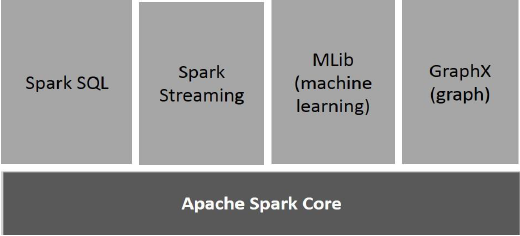
Apache Spark 核心
Spark Core 是 Spark 平台的底层通用执行引擎,所有其他功能都基于它构建。它在外部存储系统中提供内存计算和引用数据集。
Spark SQL
Spark SQL 是 Spark Core 之上的一个组件,它引入了一种称为 SchemaRDD 的新数据抽象,它为结构化和半结构化数据提供支持。
Spark 流
Spark Streaming 利用 Spark Core 的快速调度功能来执行流分析。它以小批量的形式摄取数据,并对这些小批量数据执行 RDD(弹性分布式数据集)转换。
MLlib(机器学习库)
由于基于分布式内存的 Spark 架构,MLlib 是 Spark 之上的分布式机器学习框架。根据基准,它是由 MLlib 开发人员针对交替最小二乘 (ALS) 实现完成的。 Spark MLlib 的速度是基于 Hadoop 磁盘的版本的 9 倍 Apache Mahout (在 Mahout 获得 Spark 接口之前)。
GraphX
GraphX 是基于 Spark 的分布式图形处理框架。它提供了一个用于表达图计算的 API,可以使用 Pregel 抽象 API 对用户定义的图进行建模。它还为此抽象提供了优化的运行时。