MapReduce 简介
MapReduce 是一种编程模型,用于编写可以在多个节点上并行处理大数据的应用程序。 MapReduce 提供分析大量复杂数据的分析能力。
什么是大数据?
大数据是无法使用传统计算技术处理的大型数据集的集合。例如,Facebook 或 Youtube 需要每天收集和管理的数据量,就属于大数据的范畴。但是,大数据不仅仅是规模和数量,它还涉及以下一个或多个方面:速度、多样性、数量和复杂性。
为什么选择 MapReduce?
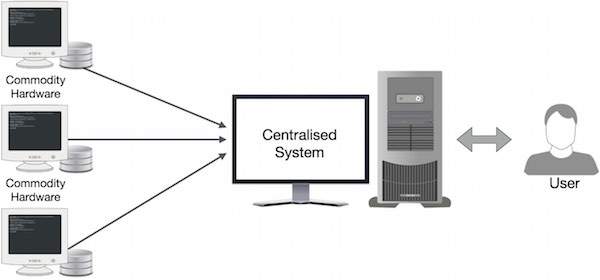
传统的企业系统通常有一个中央服务器来存储和处理数据。下图描绘了一个传统企业系统的示意图。传统模型当然不适合处理海量可扩展数据,标准数据库服务器无法容纳。此外,集中式系统在同时处理多个文件时造成了太多的瓶颈。

Google 使用一种称为 MapReduce 的算法解决了这个瓶颈问题。 MapReduce 将任务分成小部分并将它们分配给许多计算机。之后,将结果收集在一个地方并集成以形成结果数据集。
MapReduce 是如何工作的?
MapReduce 算法包含两个重要任务,即 Map 和 Reduce。
-
Map 任务获取一组数据并将其转换为另一组数据,其中单个元素被分解为元组(键值对)。
-
Reduce 任务将 Map 的输出作为输入,并将这些数据元组(键值对)组合成一组较小的元组。
reduce 任务总是在 map 作业之后执行。
现在让我们仔细看看每个阶段,并尝试了解它们的重要性。
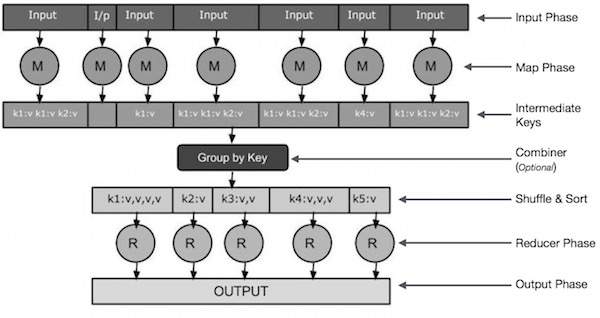
-
输入相位 :这里我们有一个Record Reader,它翻译输入文件中的每条记录,并将解析后的数据以键值对的形式发送给mapper。
-
Map : Map 是一个用户定义的函数,它接受一系列的键值对,并对它们中的每一个进行处理,生成零个或多个键值对。
-
中间键 :由mapper生成的key-value对称为中间键。
-
Combiner :combiner是一种局部Reducer,将map阶段的相似数据组合成可识别的集合。它将来自映射器的中间键作为输入,并应用用户定义的代码来聚合一个映射器的小范围内的值。它不是主要 MapReduce 算法的一部分;它是可选的。
-
随机和排序 :Reducer 任务从 Shuffle 和 Sort 步骤开始。它将分组的键值对下载到运行 Reducer 的本地机器上。各个键值对按键排序到更大的数据列表中。数据列表将等效键组合在一起,以便它们的值可以在 Reducer 任务中轻松迭代。
-
Reducer :Reducer 将分组后的键值对数据作为输入,在每一个上运行一个 Reducer 函数。在这里,可以通过多种方式对数据进行聚合、过滤和组合,并且需要进行广泛的处理。一旦执行结束,它会为最后一步提供零个或多个键值对。
-
输出相位 : 在输出阶段,我们有一个输出格式化程序,它翻译来自Reducer 函数的最终键值对,并使用记录写入器将它们写入文件。
让我们试着借助一张小图来理解 Map &f Reduce 两个任务:
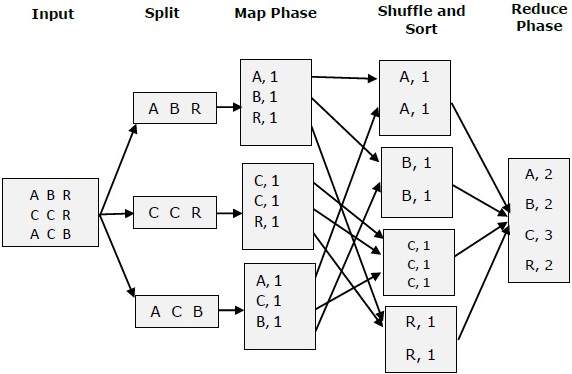
MapReduce-示例
让我们以一个真实的例子来理解 MapReduce 的强大功能。 Twitter 每天接收大约 5 亿条推文,即每秒近 3000 条推文。下图显示了 Tweeter 如何在 MapReduce 的帮助下管理其推文。
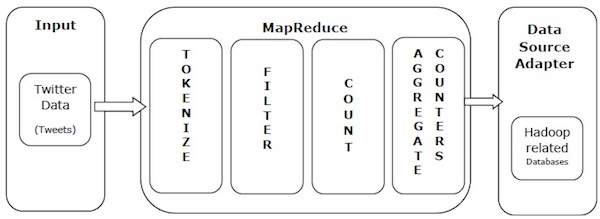
如图所示,MapReduce 算法执行以下动作:
-
Tokenize : 将推文token化成token的map,写成key-value对。
-
Filter : 从token的map中过滤掉不需要的词,将过滤后的map写成key-value对。
-
Count : 每个字生成一个记号计数器。
-
聚合计数器 : 将相似的计数器值聚合成小的可管理单元。