Python逻辑回归 拆分数据
我们有大约四万一千多条记录。如果我们使用整个数据进行模型构建,我们将不会留下任何数据进行测试。所以一般来说,我们将整个数据集分成两部分,比如 70/30 百分比。我们将 70% 的数据用于模型构建,其余数据用于测试我们创建的模型的预测准确性。你可以根据需要使用不同的分流比。
创建特征数组
在我们拆分数据之前,我们将数据分成两个数组 X 和 Y。X 数组包含我们要分析的所有特征(数据列),Y 数组是布尔值的单维数组,它是预测。为了理解这一点,让我们运行一些代码。
首先,执行以下 Python 语句创建 X 数组:
In [17]: X = data.iloc[:,1:]
检查内容 X use head 打印一些初始记录。以下屏幕显示了 X 数组的内容。
In [18]: X.head ()
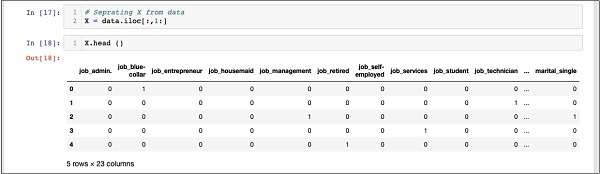
该数组有几行和 23 列。
接下来,我们将创建包含“ y ”价值观。
创建输出数组
要为预测值列创建数组,请使用以下 Python 语句:
In [19]: Y = data.iloc[:,0]
通过调用检查其内容 head .下面的屏幕输出显示了结果:
In [20]: Y.head() Out[20]: 0 0 1 0 2 1 3 0 4 1 Name: y, dtype: int64
现在,使用以下命令拆分数据:
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
这将创建四个数组,称为 X_train、Y_train、X_test 和 Y_test .和以前一样,你可以使用 head 命令检查这些数组的内容。我们将使用 X_train 和 Y_train 数组来训练我们的模型,并使用 X_test 和 Y_test 数组来进行测试和验证。
现在,我们已经准备好构建我们的分类器了。我们将在下一章中研究它。