Apache Tajo SQL 查询
本章解释了以下重要的查询。
- 谓词
- Explain
- Join
让我们继续并执行查询。
谓词
Predicate 是一个表达式,用于评估真/假值和 UNKNOWN。谓词用于 WHERE 子句和 HAVING 子句的搜索条件以及其他需要布尔值的结构。
IN 谓词
确定要测试的表达式的值是否与子查询或列表中的任何值匹配。子查询是一个普通的 SELECT 语句,它具有一列和一或多行的结果集。此列或列表中的所有表达式必须具有与要测试的表达式相同的数据类型。
语法
IN::= <expression to test> [NOT] IN (<subquery>) | (<expression1>,...)
Query
select id,name,address from mytable where id in(2,3,4);
Result
上述查询将生成以下结果。
id, name, address ------------------------------- 2, Amit, 12 old street 3, Bob, 10 cross street 4, David, 15 express avenue
查询返回记录来自 mytable 对于学生 id 2,3 和 4。
Query
select id,name,address from mytable where id not in(2,3,4);
Result
上述查询将生成以下结果。
id, name, address ------------------------------- 1, Adam, 23 new street 5, Esha, 20 garden street 6, Ganga, 25 north street 7, Jack, 2 park street 8, Leena, 24 south street 9, Mary, 5 west street 10, Peter, 16 park avenue
上面的查询返回记录来自 mytable 学生不在 2,3 和 4 的地方。
像谓词
LIKE 谓词将用于计算字符串值的第一个表达式中指定的字符串(称为要测试的值)与用于计算字符串值的第二个表达式中定义的模式进行比较。
该模式可以包含通配符的任意组合,例如:
-
下划线符号 (_),可用于代替要测试的值中的任何单个字符。
-
百分号 (%),用于替换要测试的值中任何零个或多个字符的字符串。
语法
LIKE::= <expression for calculating the string value> [NOT] LIKE <expression for calculating the string value> [ESCAPE <symbol>]
Query
select * from mytable where name like ‘A%';
Result
上述查询将生成以下结果。
id, name, address, age, mark ------------------------------- 1, Adam, 23 new street, 12, 90 2, Amit, 12 old street, 13, 95
该查询从 mytable 中返回姓名以“A”开头的学生的记录。
Query
select * from mytable where name like ‘_a%';
Result
上述查询将生成以下结果。
id, name, address, age, mark ——————————————————————————————————————- 4, David, 15 express avenue, 12, 85 6, Ganga, 25 north street, 12, 55 7, Jack, 2 park street, 12, 60 9, Mary, 5 west street, 12, 75
查询返回记录来自 mytable 那些名字以“a”作为第二个字符开头的学生。
在搜索条件中使用 NULL 值
现在让我们了解如何在搜索条件中使用 NULL 值。
语法
Predicate IS [NOT] NULL
Query
select name from mytable where name is not null;
Result
上述查询将生成以下结果。
name ------------------------------- Adam Amit Bob David Esha Ganga Jack Leena Mary Peter (10 rows, 0.076 sec, 163 B selected)
在这里,结果为真,因此它返回表中的所有名称。
Query
现在让我们检查具有 NULL 条件的查询。
default> select name from mytable where name is null;
Result
上述查询将生成以下结果。
name ------------------------------- (0 rows, 0.068 sec, 0 B selected)
Explain
Explain 用于获取查询执行计划。它显示了语句的逻辑和全局计划执行。
逻辑计划查询
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
Result
上述查询将生成以下结果。

查询结果显示给定表的逻辑计划格式。逻辑计划返回以下三个结果:
- 目标清单
- 输出架构
- 在架构中
全局计划查询
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)
Result
上述查询将生成以下结果。

在这里,全局计划显示执行块 ID、执行顺序及其信息。
Joins
SQL 连接用于组合来自两个或多个表的行。以下是不同类型的 SQL 连接:
- 内部联接
- { 左 |右 |完全 } 外连接
- 交叉连接
- 自加入
- 自然连接
考虑以下两个表来执行连接操作。
表1: 客户
| Id | Name | Address | Age |
|---|---|---|---|
| 1 | 客户 1 | 老街 23 号 | 21 |
| 2 | 客户 2 | 新街 12 号 | 23 |
| 3 | 客户 3 | 10 快捷大道 | 22 |
| 4 | 客户 4 | 快速大道 15 号 | 22 |
| 5 | 客户 5 | 花园街 20 号 | 33 |
| 6 | 客户 6 | 北街 21 号 | 25 |
表2: customer_order
| Id | Order Id | Emp Id |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
现在让我们继续对上述两个表执行 SQL 连接操作。
内部联接
当两个表中的列之间存在匹配时,内连接会从两个表中选择所有行。
语法
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;
Result
上述查询将生成以下结果。
age, empid ------------------------------- 21, 101 23, 102 22, 103 22, 104 33, 105
该查询匹配两个表中的五行。因此,它从第一个表中返回匹配的行年龄。
左外连接
左外连接保留“左”表的所有行,而不管“右”表上是否存在匹配的行。
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;
Result
上述查询将生成以下结果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105 customer6,
这里,左外连接从customers(left) 表返回name 列行,从customer_order(right) 表返回empid 列匹配行。
右外连接
右外连接保留“右”表的所有行,而不管“左”表上是否有匹配的行。
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;
Result
上述查询将生成以下结果。
name, empid ------------------------------- customer1, 101 customer2, 102 customer3, 103 customer4, 104 customer5, 105
在这里,右外连接返回 customer_order(right) 表中的 empid 行和客户表中的 name 列匹配行。
全外连接
Full Outer Join 保留左表和右表中的所有行。
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;
Result
上述查询将生成以下结果。
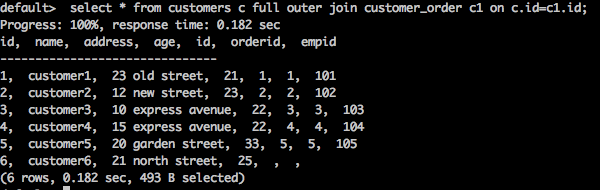
该查询从客户表和 customer_order 表中返回所有匹配和不匹配的行。
交叉连接
这将返回两个或多个连接表中记录集的笛卡尔积。
语法
SELECT * FROM table1 CROSS JOIN table2;
Query
select orderid,name,address from customers,customer_order;
Result
上述查询将生成以下结果。
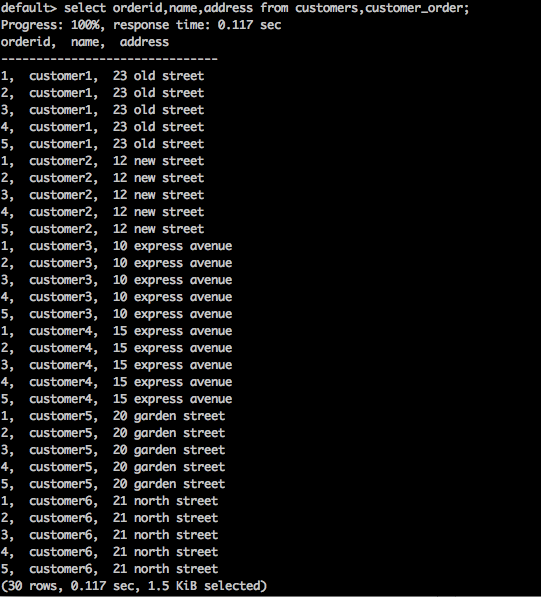
上面的查询返回表的笛卡尔积。
自然连接
自然连接不使用任何比较运算符。它不会像笛卡尔积那样连接。只有当两个关系之间至少存在一个共同属性时,我们才能执行自然连接。
语法
SELECT * FROM table1 NATURAL JOIN table2;
Query
select * from customers natural join customer_order;
Result
上述查询将生成以下结果。

在这里,两个表之间存在一个公共列 id。使用该公共列, 自然连接 连接两个表。
自加入
SQL SELF JOIN 用于将一个表连接到自身,就好像该表是两个表一样,在 SQL 语句中临时重命名至少一个表。
语法
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_filed = b.common_field
Query
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;
Result
上述查询将生成以下结果。
id, name ------------------------------- 1, customer1 2, customer2 3, customer3 4, customer4 5, customer5 6, customer6
该查询将客户表连接到自身。