HCatalog 安装
Hive、Pig、HBase 等所有 Hadoop 子项目都支持 Linux 操作系统。因此,你需要在系统上安装 Linux 风格。 HCatalog 于 2013 年 3 月 26 日与 Hive 安装合并。从 Hive-0.11.0 版本开始,HCatalog 附带 Hive 安装。因此,请按照下面给出的步骤安装 Hive,它会自动在你的系统上安装 HCatalog。
第 1 步:验证 JAVA 安装
在安装 Hive 之前,必须在你的系统上安装 Java。你可以使用以下命令来检查你的系统上是否已经安装了 Java:
$ java –version
如果你的系统上已经安装了 Java,你会看到以下响应:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果你的系统上没有安装 Java,那么你需要按照下面给出的步骤进行操作。
第 2 步:安装 Java
通过访问以下链接下载 Java(JDK <最新版本> - X64.tar.gz) http://www.oracle.com/
Then jdk-7u71-linux-x64.tar.gz 将下载到你的系统中。
通常,你会在 Downloads 文件夹中找到下载的 Java 文件。验证并提取 jdk-7u71-linux-x64.gz 使用以下命令创建文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
要使所有用户都可以使用 Java,你必须将其移动到“/usr/local/”位置。打开 root,然后键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
用于设置 PATH and JAVA_HOME 变量,添加以下命令 ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
现在使用命令验证安装 java版本 如上所述从终端。
第 3 步:验证 Hadoop 安装
在安装 Hive 之前,必须在你的系统上安装 Hadoop。让我们使用以下命令验证 Hadoop 安装:
$ hadoop version
如果你的系统上已经安装了 Hadoop,那么你将收到以下响应:
Hadoop 2.4.1 Subversion https:// svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果你的系统上未安装 Hadoop,则继续执行以下步骤:
第 4 步:下载 Hadoop
使用以下命令从 Apache Software Foundation 下载并提取 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http:// apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
第 5 步:在伪分布式模式下安装 Hadoop
以下步骤用于安装 Hadoop 2.4.1 在伪分布式模式下。
设置 Hadoop
你可以通过附加以下命令来设置 Hadoop 环境变量 ~/.bashrc file.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
现在将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
Hadoop 配置
你可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。你需要根据你的 Hadoop 基础架构对这些配置文件进行适当的更改。
$ cd $HADOOP_HOME/etc/hadoop
为了使用 Java 开发 Hadoop 程序,你必须在 hadoop-env.sh 通过替换文件 JAVA_HOME 值与 Java 在你的系统中的位置。
export JAVA_HOME=/usr/local/jdk1.7.0_71
下面给出了你必须编辑以配置 Hadoop 的文件列表。
核心站点.xml
The 核心站点.xml 文件包含诸如用于 Hadoop 实例的端口号、为文件系统分配的内存、用于存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 并在
<configuration> <property> <name>fs.default.name</name> <value>hdfs:// 本地主机:9000 </property> </configuration>
hdfs-site.xml
The hdfs-site.xml 文件包含复制数据的值、namenode 路径和本地文件系统的 datanode 路径等信息。这意味着你要存储 Hadoop 基础架构的地方。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = // 主页/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = // 主页/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在此文件的
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:// /home/hadoop/hadoopinfra/hdfs/namenode </property> <property> <name>dfs.data.dir</name> <value>file:// /home/hadoop/hadoopinfra/hdfs/datanode </property> </configuration>
注意 : 在上面的文件中,所有的属性值都是用户定义的,你可以根据你的Hadoop基础设施进行更改。
纱线站点.xml
该文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件并在该文件的
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
该文件用于指定我们使用的 MapReduce 框架。默认情况下,Hadoop 包含一个 yarn-site.xml 模板。首先,你需要从 mapred-site,xml.template to mapred-site.xml 文件使用以下命令。
$ cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件并在此文件的
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
第 6 步:验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
名称节点设置
使用命令“hdfs namenode -format”设置namenode,如下:
$ cd ~ $ hdfs namenode -format
预期结果如下:
10/24/14 21第 5 步:在伪分布式模式下安装 Hadoop55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21第 5 步:在伪分布式模式下安装 Hadoop56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21第 5 步:在伪分布式模式下安装 Hadoop56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21第 5 步:在伪分布式模式下安装 Hadoop56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21第 5 步:在伪分布式模式下安装 Hadoop56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
验证 Hadoop DFS
以下命令用于启动 DFS。执行此命令将启动你的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下:
10/24/14 21现在将所有更改应用到当前正在运行的系统中。56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
验证 Yarn 脚本
以下命令用于启动 Yarn 脚本。执行此命令将启动你的 Yarn 守护进程。
$ start-yarn.sh
预期输出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/ yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
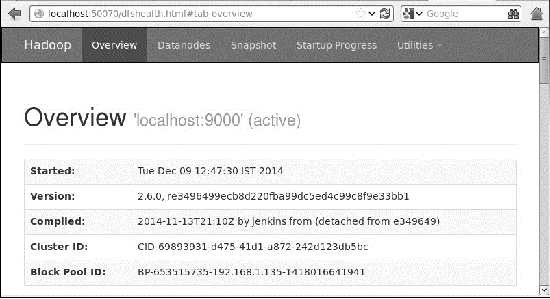
在浏览器上访问 Hadoop
访问 Hadoop 的默认端口号是 50070。使用以下 URL 在浏览器上获取 Hadoop 服务。
http:// 本地主机:50070/
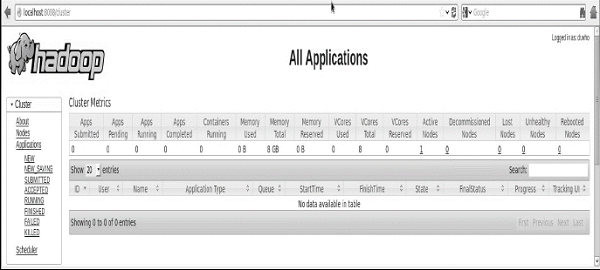
验证集群的所有应用程序
访问集群所有应用的默认端口号为8088。使用以下url访问该服务。
http:// 本地主机:8088/
完成 Hadoop 安装后,继续下一步并在系统上安装 Hive。
第 7 步:下载 Hive
我们在本教程中使用 hive-0.14.0。你可以通过访问以下链接下载它 http://apache.petsads.us/hive/hive-0.14.0/ .让我们假设它被下载到 /下载 HCatalog 。在这里,我们下载名为“ apache-hive-0.14.0-bin.tar.gz ” 对于本教程。以下命令用于验证下载:
$ cd Downloads $ ls
下载成功后会看到如下响应:
apache-hive-0.14.0-bin.tar.gz
第 8 步:安装 Hive
在你的系统上安装 Hive 需要以下步骤。让我们假设 Hive 存档下载到 /下载 HCatalog 。
提取和验证 Hive 存档
以下命令用于验证下载并解压 Hive 存档:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ ls
下载成功后会看到如下响应:
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
将文件复制到 /usr/local/hive HCatalog
我们需要从超级用户“su -”复制文件。以下命令用于将文件从提取的HCatalog 复制到 /usr/local/hive “ HCatalog 。
$ su - passwd: # cd /home/user/Download # mv apache-hive-0.14.0-bin /usr/local/hive # exit
为 Hive 设置环境
你可以通过将以下行附加到 ~/.bashrc file:
export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:. export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
以下命令用于执行 ~/.bashrc 文件。
$ source ~/.bashrc
第 9 步:配置 Hive
要使用 Hadoop 配置 Hive,你需要编辑 hive-env.sh 文件,该文件位于 $HIVE_HOME/conf HCatalog 。以下命令重定向到 Hive config 文件夹并复制模板文件:
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.sh
Edit the hive-env.sh 通过附加以下行文件:
export HADOOP_HOME=/usr/local/hadoop
至此,Hive 安装完成。现在你需要一个外部数据库服务器来配置 Metastore。我们使用 Apache Derby 数据库。
第 10 步:下载和安装 Apache Derby
请按照以下步骤下载并安装 Apache Derby:
下载 Apache Derby
以下命令用于下载 Apache Derby。下载需要一些时间。
$ cd ~ $ wget http:// archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
以下命令用于验证下载:
$ ls
下载成功后会看到如下响应:
db-derby-10.4.2.0-bin.tar.gz
提取和验证 Derby 存档
以下命令用于提取和验证 Derby 存档:
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz $ ls
下载成功后会看到如下响应:
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
将文件复制到 /usr/local/derby HCatalog
我们需要从超级用户“su -”复制。以下命令用于将文件从提取的HCatalog 复制到 /usr/local/德比 HCatalog :
$ su - passwd: # cd /home/user # mv db-derby-10.4.2.0-bin /usr/local/derby # exit
为 Derby 设置环境
你可以通过将以下行附加到 ~/.bashrc file:
export DERBY_HOME=/usr/local/derby export PATH=$PATH:$DERBY_HOME/bin export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
以下命令用于执行 ~/.bashrc 文件 :
$ source ~/.bashrc
为 Metastore 创建HCatalog
创建一个名为的HCatalog data 在 $DERBY_HOME HCatalog 中存储 Metastore 数据。
$ mkdir $DERBY_HOME/data
Derby 安装和环境设置现已完成。
第 11 步:配置 Hive 元存储
配置 Metastore 意味着向 Hive 指定数据库的存储位置。你可以通过编辑 蜂巢站点.xml 文件,它位于 $HIVE_HOME/conf HCatalog 。首先,使用以下命令复制模板文件:
$ cd $HIVE_HOME/conf $ cp hive-default.xml.template hive-site.xml
Edit
蜂巢站点.xml
并在
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:// localhost:1527/metastore_db;create = true <description>JDBC connect string for a JDBC metastore</description> </property>
创建一个名为 jpox.properties 并在其中添加以下行:
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl org.jpox.autoCreateSchema = false org.jpox.validateTables = false org.jpox.validateColumns = false org.jpox.validateConstraints = false org.jpox.storeManagerType = rdbms org.jpox.autoCreateSchema = true org.jpox.autoStartMechanismMode = checked org.jpox.transactionIsolation = read_committed javax.jdo.option.DetachAllOnCommit = true javax.jdo.option.NontransactionalRead = true javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver javax.jdo.option.ConnectionURL = jdbc:derby:// hadoop1:1527/metastore_db;create = true javax.jdo.option.ConnectionUserName = APP javax.jdo.option.ConnectionPassword = mine
第 12 步:验证 Hive 安装
在运行 Hive 之前,你需要创建 /tmp HDFS 中的文件夹和单独的 Hive 文件夹。在这里,我们使用 /用户/蜂巢/仓库 文件夹。你需要为这些新创建的文件夹设置写权限,如下图:
chmod g+w
现在在验证 Hive 之前将它们设置在 HDFS 中。使用以下命令:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
以下命令用于验证 Hive 安装:
$ cd $HIVE_HOME $ bin/hive
成功安装 Hive 后,你会看到以下响应:
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/ hive-log4j.properties Hive history =/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt …………………. hive>
你可以执行以下示例命令来显示所有表格:
hive> show tables; OK Time taken: 2.798 seconds hive>
第 13 步:验证 HCatalog 安装
使用以下命令设置系统变量 HCAT_HOME 用于 HCatalog 主页。
export HCAT_HOME = $HiVE_HOME/HCatalog
使用以下命令验证 HCatalog 安装。
cd $HCAT_HOME/bin ./hcat
如果安装成功,你会看到如下输出:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statement