HBase 安装
本章介绍如何安装和初始配置 HBase。爪哇和 Hadoop 需要继续使用 HBase,因此你必须下载并安装 系统中的 java 和 Hadoop。
安装前设置
在将 Hadoop 安装到 Linux 环境之前,我们需要使用以下命令设置 Linux ssh (安全壳)。请按照以下步骤设置 Linux 环境。
创建用户
首先,建议为Hadoop创建一个单独的用户,将Hadoop文件系统与Unix文件系统隔离开来。请按照以下步骤创建用户。
- 使用命令“su”打开根目录。
- 使用命令“useradd username”从 root 帐户创建一个用户。
- 现在你可以使用命令“su username”打开一个现有的用户帐户。
打开 Linux 终端并键入以下命令以创建用户。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 设置和密钥生成
需要 SSH 设置才能在集群上执行不同的操作,例如启动、停止和分布式守护进程 shell 操作。要对Hadoop的不同用户进行身份验证,需要为Hadoop用户提供公钥/私钥对,并与不同的用户共享。
以下命令用于使用 SSH 生成键值对。将 id_rsa.pub 中的公钥复制到 authorized_keys 中,并分别为 authorized_keys 文件提供所有者、读取和写入权限。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
验证 ssh
ssh localhost
安装 Java
Java 是 Hadoop 和 HBase 的主要学习前提。首先,你应该使用“java -version”验证系统中是否存在 java。 java version 命令的语法如下所示。
$ java -version
如果一切正常,它将为你提供以下输出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果你的系统中未安装 java,请按照以下步骤安装 java。
步骤 1
通过访问以下链接下载 java (JDK <最新版本> - X64.tar.gz) 甲骨文Java .
Then jdk-7u71-linux-x64.tar.gz 将下载到你的系统中。
步骤 2
通常你会在 Downloads 文件夹中找到下载的 java 文件。验证并提取 jdk-7u71-linux-x64.gz 使用以下命令创建文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步骤 3
要使所有用户都可以使用 java,你必须将其移动到位置“/usr/local/”。打开 root 并键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步骤 4
用于设置 PATH and JAVA_HOME 变量,添加以下命令 ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH= $PATH:$JAVA_HOME/bin
现在将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
步骤 5
使用以下命令配置 java 替代品:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
现在验证 java版本 如上所述来自终端的命令。
下载 Hadoop
安装java后,你必须安装Hadoop。首先,使用“Hadoop version”命令验证Hadoop是否存在,如下图所示。
hadoop version
如果一切正常,它将为你提供以下输出。
Hadoop 2.6.0 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
如果你的系统无法找到 Hadoop,请在你的系统中下载 Hadoop。请按照下面给出的命令执行此操作。
下载并解压 hadoop-2.6.0 从 Apache Software Foundation 使用以下命令。
$ su password: # cd /usr/local # wget http:// mirrors.advancedhosters.com/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0-src.tar.gz # tar xzf hadoop-2.6.0-src.tar.gz # mv hadoop-2.6.0/* hadoop/ # exit
安装 Hadoop
以任何所需的模式安装 Hadoop。在这里,我们以伪分布式模式演示 HBase 功能,因此以伪分布式模式安装 Hadoop。
以下步骤用于安装 Hadoop 2.4.1 .
第 1 步 - 设置 Hadoop
你可以通过附加以下命令来设置 Hadoop 环境变量 ~/.bashrc file.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
现在将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
第 2 步 - Hadoop 配置
你可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。你需要根据你的 Hadoop 基础架构对这些配置文件进行更改。
$ cd $HADOOP_HOME/etc/hadoop
为了在 java 中开发 Hadoop 程序,你必须在 hadoop-env.sh 通过替换文件 JAVA_HOME 值与系统中 java 的位置。
export JAVA_HOME=/usr/local/jdk1.7.0_71
你必须编辑以下文件来配置 Hadoop。
核心站点.xml
The 核心站点.xml 文件包含诸如用于 Hadoop 实例的端口号、为文件系统分配的内存、存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 并在
<configuration> <property> <name>fs.default.name</name> <value>hdfs:// 本地主机:9000 </property> </configuration>
hdfs-site.xml
The hdfs-site.xml 文件包含诸如复制数据的值、名称节点路径和本地文件系统的数据节点路径等信息,你希望在其中存储 Hadoop 基础架构。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = // 主页/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = // 主页/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在
<configuration> <property> <name>dfs.replication</name > <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:// /home/hadoop/hadoopinfra/hdfs/namenode </property> <property> <name>dfs.data.dir</name> <value>file:// /home/hadoop/hadoopinfra/hdfs/datanode </property> </configuration>
注意: 在上述文件中,所有属性值都是用户定义的,你可以根据你的 Hadoop 基础架构进行更改。
纱线站点.xml
该文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件并在
mapred-site.xml
该文件用于指定我们使用的 MapReduce 框架。默认情况下,Hadoop 包含一个 yarn-site.xml 模板。首先,需要从
mapred-site.xml.template
to
mapred-site.xml
文件使用以下命令。
Open
mapred-site.xml
文件并在
以下步骤用于验证 Hadoop 安装。
使用命令“hdfs namenode -format”设置名称节点,如下所示。
预期结果如下。
以下命令用于启动 dfs。执行此命令将启动你的 Hadoop 文件系统。
预期输出如下。
以下命令用于启动 yarn 脚本。执行此命令将启动你的纱线守护进程。
预期输出如下。
访问 Hadoop 的默认端口号是 50070。使用以下 url 在浏览器上获取 Hadoop 服务。
访问集群所有应用的默认端口号为8088。使用以下url访问该服务。
我们可以以三种模式中的任何一种安装 HBase:独立模式、伪分布式模式和完全分布式模式。
下载最新稳定版HBase表格
http://www.interior-dsgn.com/apache/hbase/stable/
使用“wget”命令,然后使用 tar “zxvf”命令解压。请参阅以下命令。
切换到超级用户模式并将 HBase 文件夹移动到 /usr/local,如下所示。
在继续使用 HBase 之前,你必须编辑以下文件并配置 HBase。
为 HBase 设置 java Home 并打开
hbase-env.sh
conf文件夹中的文件。编辑 JAVA_HOME 环境变量并将现有路径更改为当前 JAVA_HOME 变量,如下所示。
这将打开 HBase 的 env.sh 文件。现在替换现有的
JAVA_HOME
值与你的当前值如下所示。
这是 HBase 的主要配置文件。通过打开 /usr/local/HBase 中的 HBase 主文件夹,将数据目录设置到适当的位置。在 conf 文件夹中,你会发现几个文件,打开
hbase-site.xml
文件如下图。
在 - 的里面
hbase-site.xml
文件,你会发现
至此,HBase的安装和配置部分就成功完成了。我们可以通过使用启动 HBase
启动 hbase.sh
HBase 的 bin 文件夹中提供的脚本。为此,打开 HBase 主文件夹并运行 HBase 启动脚本,如下所示。
如果一切顺利,当你尝试运行 HBase 启动脚本时,它会提示你一条消息,说明 HBase 已启动。
现在让我们检查一下 HBase 是如何在伪分布式模式下安装的。
在继续使用 HBase 之前,请在本地系统或远程系统上配置 Hadoop 和 HDFS,并确保它们正在运行。如果 HBase 正在运行,请停止它。
hbase-site.xml
编辑 hbase-site.xml 文件以添加以下属性。
它将提到 HBase 应该在哪种模式下运行。在本地文件系统的同一文件中,使用 hdfs://// URI 语法更改 hbase.rootdir,即你的 HDFS 实例地址。我们在 localhost 的 8030 端口上运行 HDFS。
配置完成后,浏览到 HBase 主文件夹并使用以下命令启动 HBase。
注意:
在启动 HBase 之前,请确保 Hadoop 正在运行。
HBase 在 HDFS 中创建其目录。要查看创建的目录,请浏览到 Hadoop bin 并键入以下命令。
如果一切顺利,它将为你提供以下输出。
使用“local-master-backup.sh”,你最多可以启动 10 个服务器。打开 HBase 的主文件夹,master 并执行以下命令启动它。
要杀死一个备份主机,你需要它的进程 ID,它将存储在一个名为
“/tmp/hbase-USER-X-master.pid。”
你可以使用以下命令终止备份主机。
你可以使用以下命令从单个系统运行多个区域服务器。
要停止区域服务器,请使用以下命令。
成功安装 HBase 后,即可启动 HBase Shell。下面给出了启动 HBase shell 所要遵循的步骤序列。打开终端,以超级用户身份登录。
浏览 Hadoop home sbin 文件夹并启动 Hadoop 文件系统,如下所示。
浏览 HBase 根目录 bin 文件夹并启动 HBase。
这将是同一个目录。如下图所示启动它。
启动区域服务器,如下所示。
你可以使用以下命令启动 HBase shell。
这将为你提供 HBase Shell 提示,如下所示。
要访问 HBase 的 Web 界面,请在浏览器中键入以下 url。
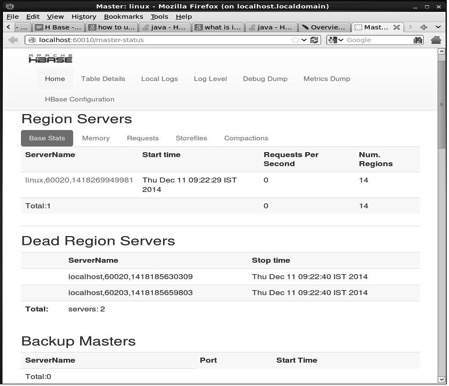
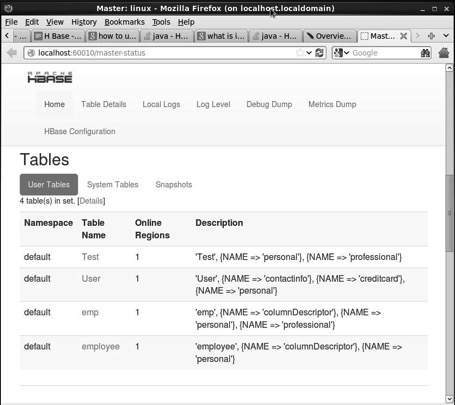
该界面列出了你当前正在运行的 Region 服务器、备份 master 和 HBase 表。
我们也可以使用 Java 库与 HBase 进行通信,但在使用 Java API 访问 HBase 之前,你需要为这些库设置类路径。
在继续编程之前,将类路径设置为 HBase 库
.bashrc
文件。打开
.bashrc
在任何编辑器中,如下所示。
在其中设置 HBase 库(HBase 中的 lib 文件夹)的类路径,如下所示。
这是为了防止在使用 java API 访问 HBase 时出现“找不到类”异常。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
$ cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证 Hadoop 安装
第 1 步 - 名称节点设置
$ cd ~
$ hdfs namenode -format
10/24/14 21JAVA_HOME55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21JAVA_HOME56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21JAVA_HOME56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21JAVA_HOME56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21JAVA_HOME56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/
第 2 步 - 验证 Hadoop dfs
$ start-dfs.sh
10/24/14 21如上所述来自终端的命令。56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
第 3 步 - 验证 Yarn 脚本
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
第 4 步 - 在浏览器上访问 Hadoop
http:// 本地主机:50070

第 5 步 - 验证集群的所有应用程序
http:// 本地主机:8088/
安装 HBase
以独立模式安装 HBase
$cd usr/local/
$wget http:// www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gz
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/
在独立模式下配置 HBase
hbase-env.sh
cd /usr/local/Hbase/conf
gedit hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.7.0
hbase-site.xml
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xml
<configuration>
// 这里你必须设置你希望 HBase 存储其文件的路径。
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
// 这里你必须设置你希望 HBase 存储其内置 zookeeper 文件的路径。
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>
$cd /usr/local/HBase/bin
$./start-hbase.sh
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out
以伪分布式模式安装 HBase
配置 HBase
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs:// localhost:8030/hbase
</property>
启动 HBase
$cd /usr/local/HBase
$bin/start-hbase.sh
检查 HDFS 中的 HBase 目录
$ ./bin/hadoop fs -ls /hbase
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs
启动和停止 Master
$ ./bin/local-master-backup.sh 2 4
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9
启动和停止 RegionServer
$ .bin/local-regionservers.sh start 2 3
$ .bin/local-regionservers.sh stop 3
启动 HBaseShell
启动 Hadoop 文件系统
$cd $HADOOP_HOME/sbin
$start-all.sh
启动 HBase
$cd /usr/local/HBase
$./bin/start-hbase.sh
启动 HBase 主服务器
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)
起始区域
$./bin/./local-regionservers.sh start 3
启动 HBase 外壳
$cd bin
$./hbase shell
2014-12-09 14将下载到你的系统中。27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18jdk-7u71-linux-x64.gz29 PST 2014
hbase(main):001:0>
HBase 网页界面
http:// 本地主机:60010
HBase 区域服务器和备份主服务器
HBase 表
设置 Java 环境
设置类路径
$ gedit ~/.bashrc
export CLASSPATH = $CLASSPATH:// 主页/hadoop/hbase/lib/*