Apache Flume 架构
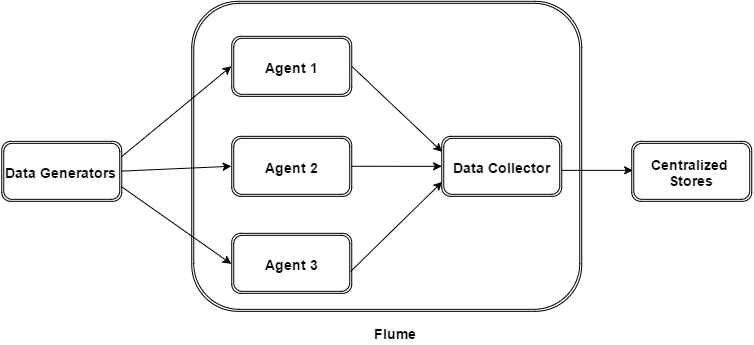
下图描述了 Flume 的基本架构。如图所示, 数据生成器 (例如 Facebook、Twitter)生成由个人 Flume 收集的数据 agents 跑在他们身上。此后,一个 数据收集器 (这也是一个代理)从代理收集数据,这些数据被聚合并推送到集中存储,例如 HDFS 或 HBase。
水槽事件
An event 是内部传输数据的基本单位 Flume .它包含一个字节数组的有效负载,该有效负载要从源传输到目标,并带有可选的标头。一个典型的 Flume 事件结构如下:

水槽代理
An agent 是 Flume 中一个独立的守护进程(JVM)。它从客户端或其他代理接收数据(事件)并将其转发到下一个目的地(接收器或代理)。 Flume 可能有不止一种代理。下图表示一个 水槽代理
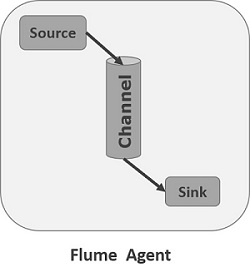
如图所示,Flume Agent 包含三个主要组件,即, source , channel , and sink .
Source
A source 是 Agent 的组件,它从数据生成器接收数据并以 Flume 事件的形式将其传输到一个或多个通道。
Apache Flume 支持多种类型的源,每个源都从指定的数据生成器接收事件。
例子 : Avro 源码、Thrift 源码、twitter 1% 源码等。
Channel
A channel 是一个临时存储,它从源接收事件并缓冲它们直到它们被接收器消耗。它充当源和汇之间的桥梁。
这些通道是完全事务性的,它们可以与任意数量的源和接收器一起工作。
例子 : JDBC通道、文件系统通道、内存通道等。
Sink
A sink 将数据存储到 HBase 和 HDFS 等集中式存储中。它使用来自通道的数据(事件)并将其传递到目的地。接收器的目的地可能是另一个代理或中央存储。
例子 : HDFS 接收器
注意 :一个flume agent可以有多个sources、sinks和channels。我们在本教程的 Flume 配置章节中列出了所有支持的源、接收器、通道。
Flume Agent 的附加成分
我们上面讨论的是代理的原始组件。除此之外,我们还有一些组件在将事件从数据生成器传输到集中式存储方面发挥着至关重要的作用。
拦截器
拦截器用于更改/检查在源和通道之间传输的水槽事件。
频道选择器
这些用于确定在多个通道的情况下选择哪个通道来传输数据。通道选择器有两种类型:
-
默认频道选择器 :这些也称为复制通道选择器,它们复制每个通道中的所有事件。
-
多路复用通道选择器 :这些决定了发送事件的通道,根据事件头中的地址。
接收器处理器
这些用于从选定的接收器组中调用特定接收器。这些用于为你的接收器创建故障转移路径或跨通道的多个接收器负载平衡事件。